


// Материалы Второй научной конференции - Новосибирск, 2001. - С. 14-16
Источник Русский филологический портал
Существующие классификации тюркских языков основаны, как правило, на трех принципах: географическом, фонетическом и морфологическом. Если первый из них заведомо не претендует на отражение истинной истории языковой группы, то попытки построить классификацию на основе двух других принципов призваны проследить, каким путем происходила дифференциация тюркских языков на протяжении их истории. Однако, как показывает изучение других языковых групп и семей, опора на фонетические или морфологические соответствия как на единственный критерий генеалогической классификации в лучшем случае оказывается недостаточной и должна быть дополнена анализом лексики изучаемых языков, особенно ее устойчивого ядра.
В настоящее время существует несколько схем классификации тюркских языков. Наибольшее распространение среди них получила классификация, предложенная в 1922 г. А.Н. Самойловичем [1]. Согласно этой классификации, основанной на фонетическом и морфологическом принципах, внутри тюркской языковой группы выделяется шесть подгрупп:
1. Булгарская (булгарский, чувашский).
2. Уйгурская (древнеуйгурский, хакасский, шорский, тувинский, тофаларский, якутский, долганский).
3. Кыпчакская (татарский, башкирский, казахский, киргизский, алтайский, карачаево-балкарский, кумыкский, крымскотатарский).
4. Чагатайская (современный уйгурский, узбекский).
5. Кыпчакско-туркменская (западные говоры узбекского языка).
6. Огузская (турецкий, азербайджанский, гагаузский, туркменский).
Иногда не выделяют отдельно кыпчакско-туркменскую подгруппу (по причине ее маргинальности и отсутствия в ней "полноценных" языков), а якутский язык включают в особую подгруппу.
Несмотря на то, что в состав тюркской группы входит значительное количество языков, задача классификации во многом упрощается тем, что ряд языков очень близки друг к другу (татарский и башкирский; казахский и каракалпакский; тувинский и тофаларский; якутский и долганский), поэтому главной проблемой является установление степени родства между заведомо близкородственными группами языков. С другой стороны, степень родства некоторых языков, особенно тех, которые бытуют в районах, близких у тюркской прародине (южная Сибирь и северный Китай), до сих пор остается невыяснен-ной, и вполне возможно, что среди них могут быть обнаружены достаточно архаичные элементы.
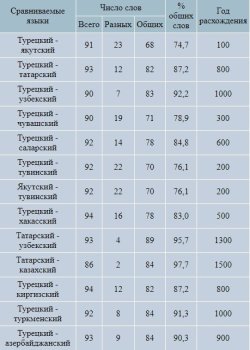
Для уточнения классификации тюркских языков нами было предпринято предварительное исследование степени их генетической близости при помощи метода глоттохронологии. Этот метод, разработанный американским ученым М. Сводешом в начале 1950-х гг. и существенно откорректированный С.А. Старостиным в середине 1980-гг. [2], является важным инструментом проникновения в отдаленную историю генетически родственным языков. Исходной точкой исследования стало сопоставление стословного списка М. Сводеша для турецкого языка с другими языками тюркской группы. В ряде случаев проводилось также сопоставление стословного списка и по другим языкам. В соответствии с методикой С.А. Старостина из списков исключались заимствования, а коэффициент сохранности лексики был принят равным 91 % за тысячелетие.
Результаты сопоставления списков представлены в приводимой ниже таблице.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Примечание: Год предполагаемого расхождения языков округлен с точностью до 100 лет.
Графически процесс расхождения тюркских языков может быть представлен в виде дендрограммы, отражающей относительную близость и удаленность различных языков друг от друга. Несмотря на предварительный характер анализа, он позволяет сделать следующие выводы:
1. Разделение тюрских языков на четыре самые древние ветви (якутскую, тувинскую, булгарскую и западную) произошло практически одновременно в течение трех первых веков нашей эры.
2. Якутский и тувинский язык не обнаруживают особой близости друг к другу и должны рассматриваться как принадлежашие к разным подгруппам.
3. Другие тюрские языки Сибири и Китая (были рассмотрены хакасский и саларский), видимо, относятся к основной (западной) подгруппе тюрских языков, хотя и выделились из нее ранее, чем остальные языки этой подгруппы.
4. Булгарская подгруппа (чувашский язык) равноудалена от других подгрупп тюркских языков и выделилась из единого тюркского праязыка не ранее (а, возможно, даже несколько позже), чем другие ветви.
5. Языки, включаемые в огузскую подгруппу (турецкий, азербайджанский и туркменский) не обнаруживают особой близости друг к другу; различие между ними даже больше, чем между языками кыпчакской (татарский, казахский) и чагатайской (узбекский) подгрупп.
6. Результаты глоттохронологического анализа удивительно хорошо совпадают с данными истории и поэтому могут рассматриваться как достоверные.
Таким образом, согласно предварительной классификации тюрских языков на основе глоттохронологии могут быть выделены четыре практически равноправные подгруппы:
1. Якутская подгруппа: якутский, долганский.
2. Тувинская подгруппа: тувинский, тофаларский.
3. Булгарская подгруппа: чувашский.
4. Западная подгруппа: татарский, башкирский, казахский, турецкий, туркменский, азербайджанский, хакасский, саларский и все остальные тюркские языки.
Дальнейшие исследования с провлечением данных всех тюрских языков помогут восстановить более полную картину их глоттохронологической классификации.
Список литературы:
[1] Самойлович А.Н. Некоторые дополнения к классификации турецких языков. Пг., 1922. - С. 15. Подробно о различных схемах классификации тюрских языков см.: Гаджиева Н.З. К вопросу о классификации тюрских языков и диалектов // Теоретические основы классификации языков мира. М., 1980. - С. 100-126; Гаджиева Н.З. Тюркские языки // Лингвистический энциклопедический словарь. М., 1990. - С. 527.
[2] Старостин С.А. Сравнительно-историческое языкознание и лексикостатистика // Лингвистическая реконструкция и древнейшая история Востока (Материалы к дискуссиям международной конференции). Т. 1. М., 1989. - С. 3-39.
Рекомендуемые комментарии
Комментариев нет